

Learn More
Pricing
Author: Baojian Shen
Senior Product Manager, Tencent WeTest
The gaming industry is entering the "intelligent" second half of industrialization, where automated testing has evolved from a single tool attribute to a core competitive barrier. This research report aims to paint a clear panorama of the game AI automation landscape: vertically tracing the technological evolution from rule-based scripts to generative intelligent agents (LLM-Agent), and horizontally analyzing opportunities and challenges across the industrial value chain. Through insights into cutting-edge technologies and the engineering implementation gap, we aim to provide valuable guidance for future quality efficiency system architecture.
The rise of game AI automated testing is no accident but an inevitable trend driven by multiple structural changes in the industry. The gaming industry is currently experiencing unprecedented complexity and scale challenges, with traditional manual QA models struggling to meet modern game development quality assurance needs.
Rising Development Costs represent the primary driver. The development cost of AAA titles has soared to the $150-300 million range, with content volume growing exponentially. Open-world games, for instance, may contain hundreds of hours of main and side content, thousands of interactive NPCs, and nearly infinite player behavior combinations. Even with hundreds of person-days invested, traditional QA teams struggle to cover all branching paths and edge cases.
Games-as-a-Service (GaaS) Model further amplifies testing pressure. GaaS requires continuous high-frequency updates post-launch—new seasons, characters, and events on weekly or even daily iteration cycles. Each update brings substantial regression testing demands. Relying purely on manual execution proves both costly and difficult to ensure timely and consistent testing.
Systemic Increase in Game Complexity constitutes the third driver. Open-world non-linear narratives allow players to trigger storylines in any order; MMO high-concurrency scenarios require simulating thousands of simultaneous players; Roguelike random generation makes each playthrough unique. These design paradigms cause test cases to explode, rendering traditional "exhaustive testing" methodology completely obsolete.
Elevated Player Quality Expectations form the final market pressure. In the social media era, a glaring bug can spark public outcry within hours, directly impacting the game's commercial performance and brand reputation. Player tolerance for bugs has diminished continuously; "perfect on launch" has become an industry's implicit standard.
The global game AI testing market is experiencing rapid expansion. According to 2024 industry research, the global game AI testing market was valued at approximately $412 million, projected to grow to $2.16 billion by 2033, corresponding to a compound annual growth rate (CAGR) of 20.1%. This growth rate significantly exceeds the overall gaming industry expansion, reflecting AI testing technology transitioning from "optional" to "necessity" during a critical window.
From a regional perspective, Chinese gaming enterprises have achieved an 86.36% AI technology application rate, significantly higher than the global average of 50-55%. This gap partly stems from China's competitive mobile gaming market environment—aggressive iteration and rapid launch cycles forced vendors to embrace automation tools earlier.
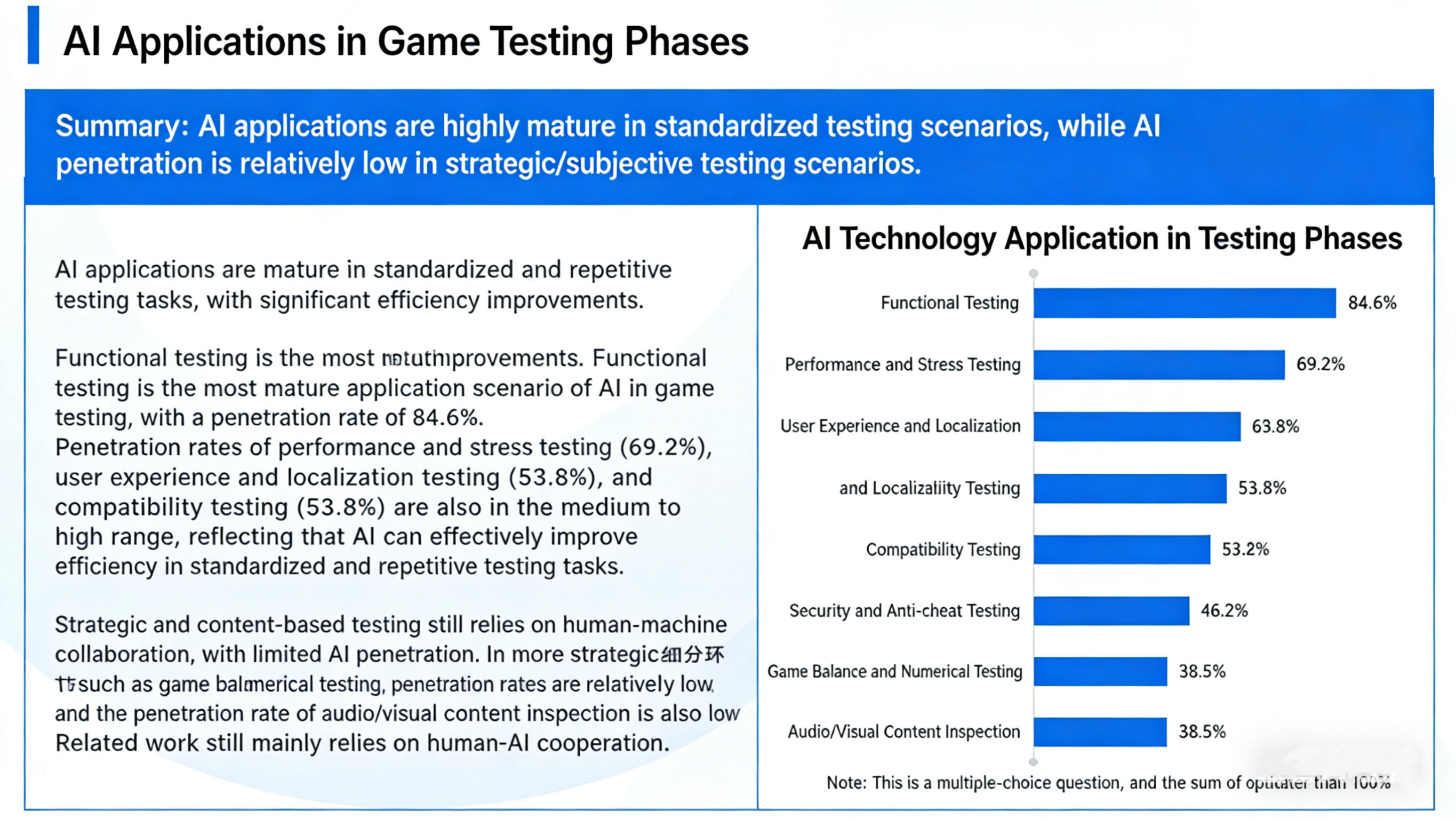
Scenario-Specific Technology Penetration Rates:
Functional and performance testing have entered mature application phases, while advanced scenarios like balance testing remain exploratory, harboring tremendous technological innovation opportunities.
The game AI automated testing value chain exhibits a clear three-layer structure, with participants interdependent and co-evolving:
Upstream: Technology Providers
The upstream comprises two major blocks: the AI Model Layer and Compute Infrastructure Layer. Core players in the AI model layer include OpenAI (GPT series), Google DeepMind (Gemini, SIMA), Microsoft (Copilot ecosystem), and open-source communities (Hugging Face). These institutions provide the foundational large language model capabilities driving intelligent testing—the "engine" of the entire tech stack. The compute layer is dominated by NVIDIA (GPU hardware) and cloud service providers (AWS, Azure, Tencent Cloud, Alibaba Cloud), providing necessary computational resources for model training and inference.
Midstream: Solution/Tool Providers
The midstream represents the most active innovation hub in the value chain, exhibiting a multi-faceted landscape of "engine self-research + third-party SaaS + AI startups":
Downstream: Game Studios/Publishers
Downstream industry leaders have established in-house AI testing platforms. Tencent AI Lab (Juewu), NetEase Fuxi Lab, Ubisoft La Forge, miHoYo, among others, operate dedicated internal AI labs, translating cutting-edge technology into productivity tools. These self-developed capabilities not only serve internal projects but also contribute back to the industry ecosystem through open-source initiatives or commercialization.
Current game AI testing solutions can be categorized into three major technological paradigms, each with distinct applicable scenarios and limitations:
|
Solution Paradigm |
Representative Tools |
Core Advantages |
Primary Limitations |
Applicable Scenarios |
|
Traditional Script Automation |
Airtest, Poco |
High stability, gentle learning curve |
Fragile scripts, exponential maintenance costs |
UI regression, fixed workflows |
|
Reinforcement Learning |
ML-Agents, Juewu |
Discovers edge cases humans miss |
Difficult reward engineering, complex environment setup |
Numeric balance, competitive testing |
|
Large Language Models |
SIMA 2, GPT-4V |
Strong generalization, logical reasoning |
High costs, hallucination risks |
Open worlds, complex tasks |
Game AI automated testing evolution represents a transition from "hard-coded instructions" to "general cognitive intelligence." This evolution transcends mere algorithmic iteration—it encompasses comprehensive enhancement in perception dimensions and decision-making depth. Understanding where the technology originates, where it stands today, and where it's heading is crucial for grasping industry trends.
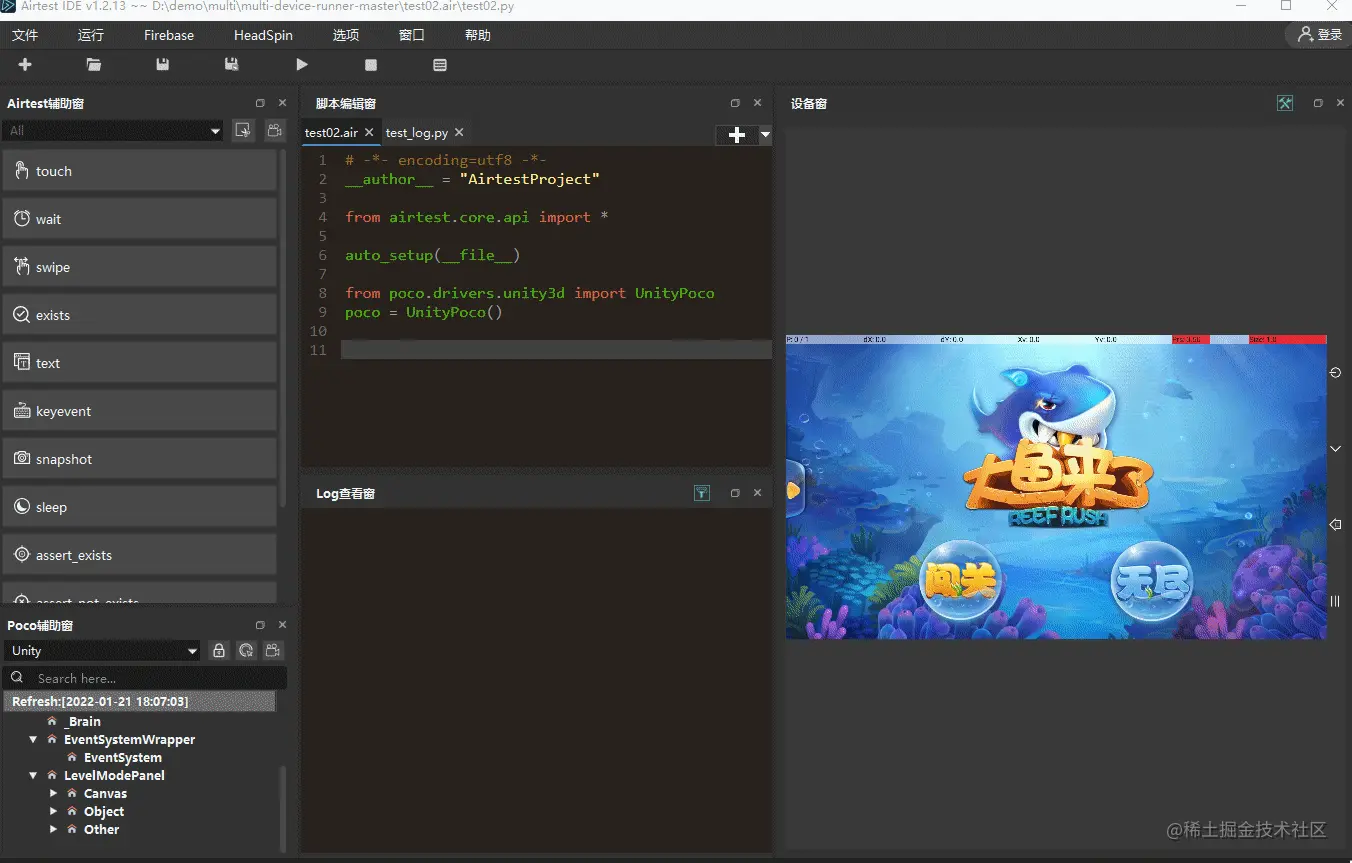
Script-based automation represents the starting point of game testing automation, with its core technology stack encompassing coordinate clicking, image recognition (based on OpenCV), and UI control tree parsing. QA personnel define fixed operation sequences (e.g., "click coordinate (100,200)" → "wait 3 seconds" → "verify image A appears") either through recording or manual scripting, which the automation framework executes step-by-step.
NetEase's Airtest exemplifies this stage, packaging image recognition and script execution into a user-friendly IDE enabling non-technical QA professionals to quickly onboard. However, script automation's fundamental limitation lies in its "rigid" nature: it can only execute predetermined steps sequentially, cannot handle random events (such as pop-ups or interface changes from network delays), and any modification to game content risks script failure (Fragility). This "pull one thread and unravel the whole sweater" brittleness renders it inadequate in modern games' rapid iteration environments.
To overcome script automation's rigidity, exploratory automation introduces randomness and basic intelligence. Core technologies include:
Exploratory automation has reached mature application status, representing the "standard configuration" for most gaming companies' testing approaches. Its limitation lies in lacking logical depth: bot behavior is essentially random or preset, unable to understand game rules or conduct targeted functionality testing.
Reinforcement Learning (RL) models testing as sequential decision problems, with agents learning optimal strategies through environment interaction. Core technologies include:
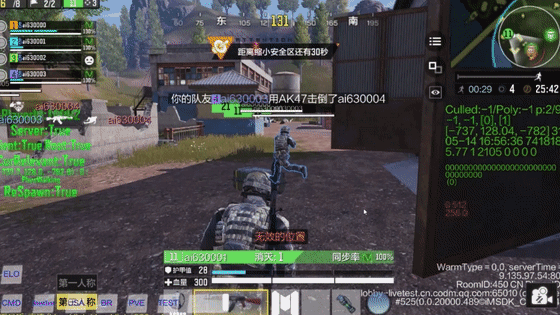
RL solution typical applications include: competitive game numeric balance testing (Tencent's Juewu for Honor of Kings hero balance verification), racing game pathfinding testing, and level difficulty assessment. Its advantages include discovering edge cases humans struggle to reach; its pain points are equally apparent: reward function design proves extraordinarily difficult (Reward Engineering)—crafting rewards that guide AI to discover bugs without "gaming" the system is an art requiring extensive experience. Additionally, testing environment construction and debugging consume significant time, struggling to meet rapid iteration demands.
Generative intelligent agents centered on Large Language Models (LLM) and Vision Language Models (VLM) represent the future direction of game AI testing. Core technological breakthroughs manifest across four dimensions:
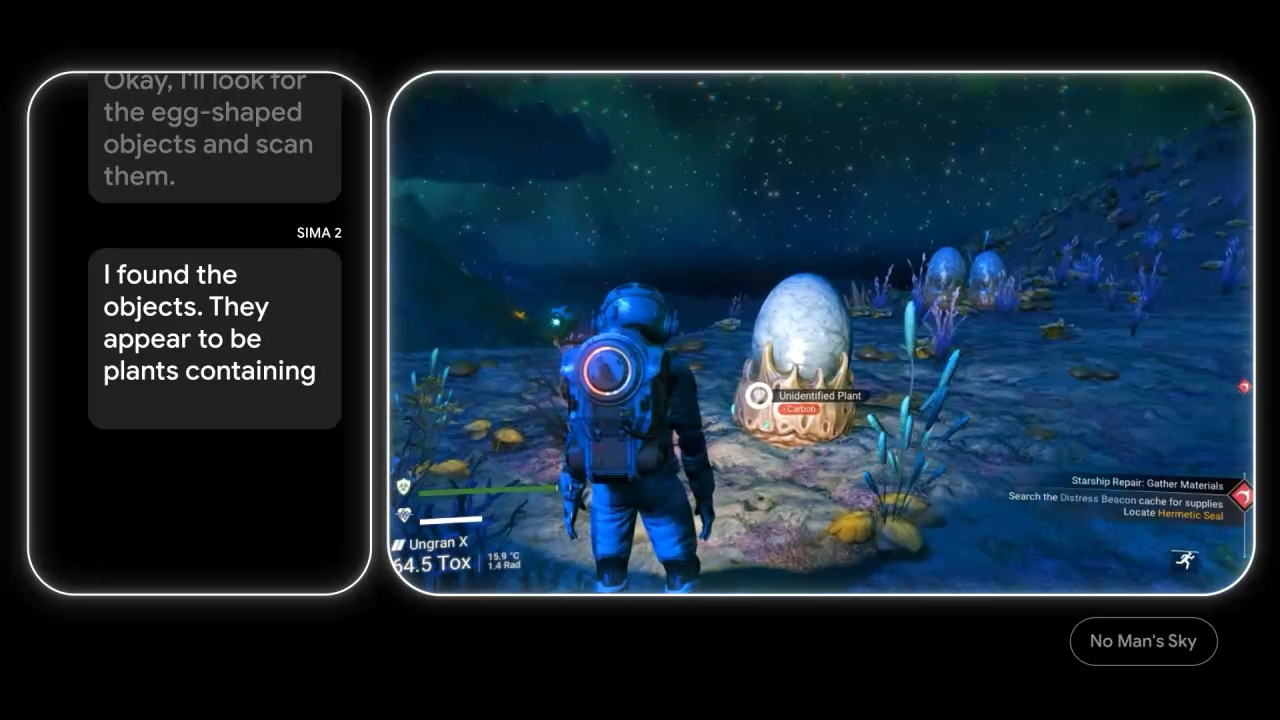
Google DeepMind's SIMA 2 represents this stage's benchmark project. Integrating the Gemini model, it possesses goal-setting, logical reasoning, and conversational abilities, demonstrating 2-3× improved task success rates compared to its predecessor in 3D virtual environments.
|
Evolution Stage |
Core Technology |
Representative Tools |
Applicable Scenarios |
Primary Limitations |
Technology Maturity |
|
Script Automation |
OpenCV, UI control tree |
Airtest, Poco |
UI verification, fixed workflows |
Fragile scripts, high maintenance |
Extremely High (Mature) |
|
Exploratory Automation |
Monkey, Behavior Trees, NavMesh |
Android Monkey |
Crash detection, basic pathfinding |
Lacks logical depth |
High (Stable) |
|
Reinforcement Learning |
PPO/SAC, Imitation Learning |
ML-Agents, Juewu |
Numeric balance, competitive testing |
Difficult reward engineering |
Medium (Growth) |
|
Generative Agents |
LLM/VLM, ReAct |
SIMA 2, GPT-4V |
Complex tasks, unmanned testing |
Reasoning latency, hallucination |
Early Stage (Emerging) |
The inherent logic of technological iteration can be distilled into two keywords: "Decoupling" and "Generalization". Early solutions tightly coupled to specific engines or SDKs with poor cross-platform capability; modern solutions achieve complete decoupling between testing tools and game engines through pure visual perception. Simultaneously, evolution from preset scripts to autonomous decision-making equips AI to handle non-linear narratives and open-world random events with universal applicability.
This section dissects the four-layer technical architecture of game AI automated testing: Perception, Decision-Making, Action, and Evaluation layers. This is fundamental to understanding implementation details and assessing solution feasibility.
The perception layer acquires information from games, serving as the testing system's "eyes." According to information acquisition methods, it divides into two technological approaches:
Ground Truth Acquisition (White-Box Perception): Directly reading data from game engine memory—character coordinates, HP values, quest status, inventory contents, etc. This approach ensures accuracy and low latency but exhibits high invasiveness—requiring SDK embedding or specific function hooking within games, highly dependent on concrete engines, with poor cross-project reusability. NetEase's Poco framework adopts this route, obtaining UI control trees by injecting Python runtime environments into games.
Visual Perception (Black-Box Perception): Purely image recognition-based from game visuals. AI directly "observes" screen captures or video streams, employing computer vision (traditional OpenCV or deep learning CNNs) to recognize UI elements, characters, and scene objects. This approach offers exceptional universality—engine-agnostic, no source code access required—but operates relatively slowly (involving image processing) with potentially degraded accuracy in complex scenes.
These routes aren't mutually exclusive. Practical engineering often employs "hybrid perception" strategies: acquiring critical data (economic systems, combat values) via Ground Truth for precision; relying on visual perception for generic interactions (menu navigation, dialog selection) to enhance flexibility. Microsoft Xbox's testing platform exemplifies this "black-box + white-box" hybrid model.
The decision-making layer serves as the testing agent's "brain," determining next actions based on perceived information. Under the new LLM-driven paradigm, the core is the ReAct framework.
ReAct (Reason + Act) framework, introduced by Google Research in November 2022, operates on the principle of alternating LLM generation of "reasoning traces" and "action instructions" during task execution. A typical ReAct cycle proceeds as follows:
ReAct's advantages include interpretability and self-correction capabilities. Explicit reasoning traces allow developers to trace AI's decision logic; encountering obstacles (e.g., NPC not at expected location), the reasoning process triggers strategy adjustment rather than simple deadlock.
Prompt Engineering represents another critical decision-layer technology. How to craft prompts enabling LLMs to role-play as "bug-hunting QA engineers" fundamentally impacts testing effectiveness. Typical testing prompts include: character setting ("you are a senior QA engineer"), behavioral guidelines ("maintain high alertness to anomalies"), output format specifications ("report issues in JSON format"), and minimal examples (Few-shot Learning).
The action layer converts high-level instructions from the decision layer into low-level input signals, bridging the AI's logic and game world.
Action space mapping represents this layer's core challenge: LLM outputs natural language or structured text (e.g., "Jump", "Attack", "Open_Inventory"), while games receive keyboard/mouse/gamepad physical signals. Mapping typically employs predefined "action dictionaries"—corresponding each high-level action to specific key combinations or coordinate clicks. Examples include:
Microsoft Xbox's testing platform adopts this "black-box" interaction model, injecting input signals through virtual controller interfaces, ensuring testing processes perfectly match real player behavior without test framework-specific privileges masking potential bugs.
For mobile games, tools like Airtest employ ADB (Android Debug Bridge) or iOS XCTest frameworks to simulate touch events; for PC/console games, DirectInput/XInput interfaces enable gamepad signal injection.
The evaluation layer addresses "how does AI recognize bugs?"—a critical closing link in automation testing loops.
Crash and Exception Log Monitoring represent the most basic evaluation means. Continuously monitoring game process standard output (stdout/stderr), system logs (like Android Logcat), and game-embedded error reporting modules captures crashes, exceptions, and warnings in real-time. Upon crash detection, the testing framework immediately preserves scene snapshots (screenshots, logs, operation replay) for subsequent investigation.
Visual Defect Detection leverages deep learning models identifying anomalies. CNN-based approaches detect typical graphics bugs: clipping (characters/objects embedded in walls/floors), frame drops, texture loss (black blocks/corrupted displays), Z-fighting (overlapping faces flickering). EA SEED Lab research demonstrates trained CNNs achieve human reviewer parity in graphics defect detection accuracy.
Logic Assertions represent higher-order evaluation methods. LLMs understanding game rules automatically generate verification logic. For example, completing a transaction, AI asserts "player coins should decrease by X, inventory should gain item Y". Actual state mismatches indicate logic bugs. This approach depends on AI's deep game mechanic understanding, representing LLM-driven testing's core value proposition.
Turing Test for Bots evaluates whether bot behavior resembles real players. This evaluation dimension proves particularly important in anti-cheat and numeric balance testing: excessive behavior pattern divergence from real players (e.g., "optimal" movement paths, overly consistent reaction times) may render test results unrepresentative of genuine player experiences. Modl.ai's "Procedural Personas" simulates different player types (violent explorers, path-dependent players, social players) enhancing bot behavior diversity and realism.
Opportunity One: QA Copilot
AI no longer pursues complete human replacement but serves as testing personnel's intelligent assistant. Testers issue natural language instructions (e.g., "test all Boss phase-two skill damage"), AI automatically decomposes tasks, executes testing, and summarizes results. This human-machine collaboration mode leverages AI's efficiency advantages while preserving human judgment and creativity, dramatically reducing automated testing's technical barrier.
Opportunity Two: Automated Numeric Balance
Leveraging AI like Tencent's Juewu for millions of self-play matches simulates months of server-launch player ecosystems in hours. AI rapidly identifies overpowered or underpowered characters/equipment/skills, providing precise feedback to numeric designers. Compared to traditional manual testing or limited player testing, AI-driven balance verification demonstrates overwhelming speed and coverage advantages.
Opportunity Three: Testing-Production Integration
High-intelligence bots trained during testing phases directly transform into in-game NPCs. This means development investment achieves "dual benefits": identical AI capabilities serve both QA teams and game design teams. Tested combat bots become high-difficulty in-game enemies; explored bots transform into player AI teammates. This "testing-production integration" model significantly elevates AI research ROI.
Opportunity Four: Universal Cross-Platform Solutions
Pure vision-driven approaches (like SIMA 2) require no engine SDKs or source code access. This enables identical testing AI to support mobile, PC, console, and cloud gaming—truly achieving "develop once, deploy everywhere." The first to launch mature universal cross-platform testing AI will command market advantage.
Challenge One: LLM Hallucination
Generative agents may "fabricate" non-existent bug reports or misunderstand logical assertions. For instance, AI might misclassify normal game mechanics as bugs or add never-occurred details when recounting issues. This hallucination severely compromises bug report credibility, requiring strict multi-stage verification mechanisms (bug reproduction confirmation, human review sampling).
Challenge Two: Reasoning Cost & Latency
Calling top-tier models (e.g., GPT-4) for per-frame decision-making proves both expensive and slow. At 30 fps gameplay, per-frame cloud API calls render both latency and cost completely unacceptable. Solutions include: deploying edge-side small models (SLM) for routine decisions, calling large models only at key nodes; knowledge distillation transferring large model capabilities to lightweight models; or "batch decision" strategies, performing full reasoning every N frames.
Challenge Three: Long-Horizon Task Memory Loss
During extended MMO quest chains (e.g., multi-hour main storylines), AI easily "forgets" original testing objectives, entering meaningless loops or deviating from planned paths. While current LLMs' context windows extend to hundreds of thousands of tokens, maintaining long-horizon task state consistency remains challenging. Advanced vector databases, external memory modules, or hierarchical goal management mechanisms represent technological directions addressing this challenge.
|
Conference Name |
Domain Focus |
Value Position |
|
GDC AI Summit |
Industry Latest Practices |
Focuses on firsthand experience sharing of AI bot construction and production deployment |
|
IEEE CoG (Conference on Games) |
Academic Frontier |
RL navigation, automated level evaluation and other theoretical research |
|
SIGGRAPH |
Visual & Graphics AI |
AI applications in physics simulation, motion synthesis, visual rendering |
Core Recommended Papers:
5.3.1 Google DeepMind: SIMA & SIMA 2
SIMA (Scalable Instructable Multiworld Agent) represents DeepMind's universal 3D virtual environment agent, operating games via pure visual input and natural language instructions without any engine interfaces or source code access. Upgraded SIMA 2 integrates Gemini, possessing enhanced goal-setting, logical reasoning, and conversational abilities. Standardized testing shows SIMA 2's task success rate improved 2-3× over its predecessor, demonstrating immense potential of LLM-driven testing.
5.3.2 NetEase Fuxi Lab: Intelligent Task Regression
Fuxi Lab's "Intelligent Task Regression Testing" technology models RPG tasks as sequential decision problems, training agents to autonomously complete tasks via reinforcement learning. In the Nirvana in Fire Online project, AI covers 500+ main and side quests, reducing testing cycles from "weeks" to "hours," substantially improving version iteration efficiency.
5.3.3 Tencent AI Lab: Juewu Balance Testing
"Juewu" is Tencent AI Lab's MOBA game AI system learning Honor of Kings strategies through millions of self-play matches. In balance testing scenarios, Juewu rapidly evaluates new hero/equipment numeric strength, providing design teams win-rate references and adjustment suggestions with 95% accuracy.
5.3.4 Xbox Game Studios: Cloud Path Testing Vision
Xbox Game Studios leadership proposed "cloud path testing" vision: leveraging AI bots running tens of thousands of parallel game instances in cloud, each executing different test paths independently. This massive parallelization completes in minimal time what traditional manual testing requires months to achieve.
5.3.5 Ubisoft La Forge: ML Bots & Toxicity Detection
Ubisoft's research division La Forge shared ML bot construction practices at GDC AI Summit. They developed "ToxBuster" system for chat toxicity detection and employed ML bots for open-world path verification and boundary detection.
5.3.6 Modl.ai: Procedural Personas
Modl.ai, focused on game AI testing SaaS, innovated "Procedural Personas"—parameterized configuration generating diverse virtual players (violent explorers, path-dependent players, social players), enhancing test bot behavioral diversity and alignment with real player distribution.
5.3.7 WeTest Acorn AI Game Testing Agent
Acorn AI Game Testing Agent proposes engine plugin-based automated testing solutions. Through structured knowledge bases and multi-agent collaboration, achieving closed-loop from natural language instruction to game task execution, significantly elevating test coverage and adaptability.
marketintelo.com, 2024. Game Testing AI Market Research Report 2033. Game Testing AI Market Research Report 2033
gamelook.com.cn, 2025-12-23. 调研22家国内大厂,游戏工委发布《游戏企业AI技术应用报告》. 调研22家国内大厂,游戏工委发布《游戏企业AI技术应用报告》 | 游戏大观 | GameLook.com.cn
gameinstitute.qq.com. 王者荣耀的人工智能进行时 - 腾讯游戏学堂. http://gameinstitute.qq.com/news/detail/161
3dmgame.com, 2020-04-27. 国内首创!伏羲×雷火再发力,AI加盟任务回归测试. 国内首创!伏羲×雷火再发力,AI加盟任务回归测试_3DM单机
keywordsstudios.com, 2025-02-04. Supercharge Your Game Localization and Testing: The Power of AI. Supercharge Your Game Localization and Testing: The Power of AI and Strategic Partnerships | Keywords Studios Limited
deepmind.google, 2025-11-13. SIMA 2: A Gemini-Powered AI Agent for 3D Virtual Worlds. https://deepmind.google/blog/sima-2-an-agent-that-plays-reasons-and-learns-with-you-in-virtual-3d-worlds
chinadaily.com.cn, 2021-07-26. 绝悟AI参展游戏开发者大会,AI深入游戏产业全链路. 绝悟AI参展游戏开发者大会,AI深入游戏产业全链路 - 中国日报网
github.com. Unity-Technologies/ml-agents. GitHub - Unity-Technologies/ml-agents: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents using deep reinforcement learning and imitation learning.
juejin.cn, 2022-01-23. 网易UI自动化测试探索:Airtest+Poco. 网易UI自动化测试探索:Airtest+Poco对拥有非常多大型游戏项目的网易游戏来说,UI自动化测试是非常必要的。虽然 - 掘金
airtest.doc.io.netease.com. Poco介绍 - Airtest Project Docs. Poco介绍 - Airtest Project Docs
80.lv, 2022-09-06. Xbox's Matt Booty "Dreams" of Using AI Bots for QA Testing. Xbox's Matt Booty "Dreams" of Using AI Bots for QA Testing
modl.ai. Modl.ai Official Website. Home
gdcvault.com, 2024. AI Summit: Building ML Bots at Ubisoft La Forge. GDC Vault - AI Summit: Building ML Bots at Ubisoft La Forge: From Research to Production
ubisoft.com. Ubisoft La Forge Publications. Ubisoft La Forge | Ubisoft
geeksforgeeks.org, 2025-07-12. Monkey Software Testing. https://geeksforgeeks.org/software-testing/monkey-software-testing
developer.android.com, 2023-04-12. UI/Application Exerciser Monkey. https://developer.android.com/studio/test/other-testing-tools/monkey
research.google, 2022-11-08. ReAct: Synergizing Reasoning and Acting in Language Models. https://research.google/blog/react-synergizing-reasoning-and-acting-in-language-models
sciencedirect.com, 2025. A state-aware, hierarchical deep learning framework for automated visual glitch detection. A state-aware, hierarchical deep learning framework for automated visual glitch detection in games - ScienceDirect
ea.com. Graphical Glitch Detection in Video Games Using Convolutional Neural Networks. Graphical Glitch Detection in Video Games Using Convolutional Neural Networks
dev.to, 2026-01-03. Why Reasoning and Acting is the Standard for LLM Agents. Demystifying ReAct: Why Reasoning and Acting is the Standard for LLM Agents - DEV Community
Baojian Shen is a Senior Product Manager at Tencent WeTest with over 10 years of experience in software testing and game testing. He leads product planning and solution development for testing platforms and quality engineering initiatives, focusing on automated testing, compatibility testing, performance testing, game testing solutions, and scalable test platform development. Baojian’s work bridges practical testing challenges and product strategy, with emphasis on AI-driven testing, quality engineering, and implementable, evidence-based methodologies. He regularly shares industry insights grounded in real-world projects and measurable outcomes.